The One Where the Team Picks a Font¶
Byte-Sized Updates¶
- Collision Solving: Implemented rudimentary collision solving, but still have lots of distance to cover for a decent collision response system.
- Level Loading: Got loading from startup level to another prebuilt loader in the engine working. There were a few catching points, but overall went smoothly.
- Asset Processing Tool: Built an asset processing tool to process the Collada files (
.dae) more efficiently, easier than in the past. - GUI: Added more to the GUI system by fully integrating fonts, so font size and type can be changed per GUI function.
- AI: Implemented an AI pathfinding system by combining vector flow fields and steering behaviors.
- Full-Feature Game Demo: Started development of the target game that the engine is being built for, which forced some other smaller features.

Collision Solving¶
We started collision detection all the way back in week 6, and it's been growing pretty nicely. At this point, we have fully functional sphere and box collisions and partially functional capsule collisions, which means we can trigger functions in the game in response to when some collider volume enters, exits, or stays inside of another collider volume, which is immensely helpful with a lot of game concepts like trigger points.
Unfortunately, figuring out that the collider volumes are intersecting is only half the battle. Now that we've got the collisions getting detected, we need to take it one step further and move colliders away from their counterparts whenever an intersection occurs. This is called collision solving, and it's a crucial concept in video games, where things don't physically inhabit space and so we can't rely on the convenience of physics to help us keep things real. Depending on who you ask, there are three distinct parts of collision solving:
- The detection. This is where you figure out that two colliders are intersecting with one another, and it's the part that we (mostly) already have figured out.
- The resolution. This is where you take the two colliders and figure out where exactly they should be moved to so that they are no longer intersecting. This takes the previous problem of collision detection and expands upon it, because we now need not just the fact that the colliders are intersecting but also info on where exactly they're intersecting.
- The iteration. Now, you technically don't need this one, but you probably don't have a very good generalized solution if you have no need for iteration in your collision solver. Iteration is used in collision solving to determine that your resolutions are acceptable. Let's illustrate with an example: Take three sphere colliders. Two of them start intersecting like this, and the other one is just barely off to the side:
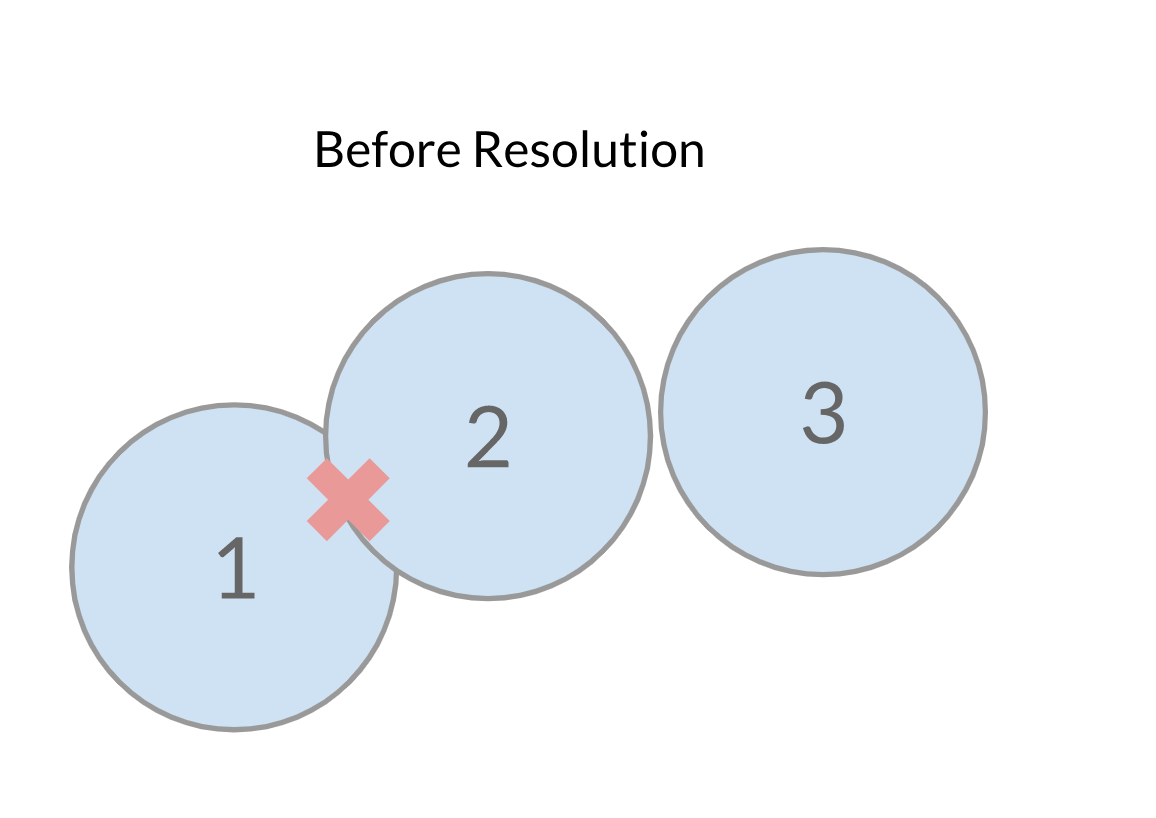 After we've resolved the first collision, this is what we end up with:
After we've resolved the first collision, this is what we end up with: 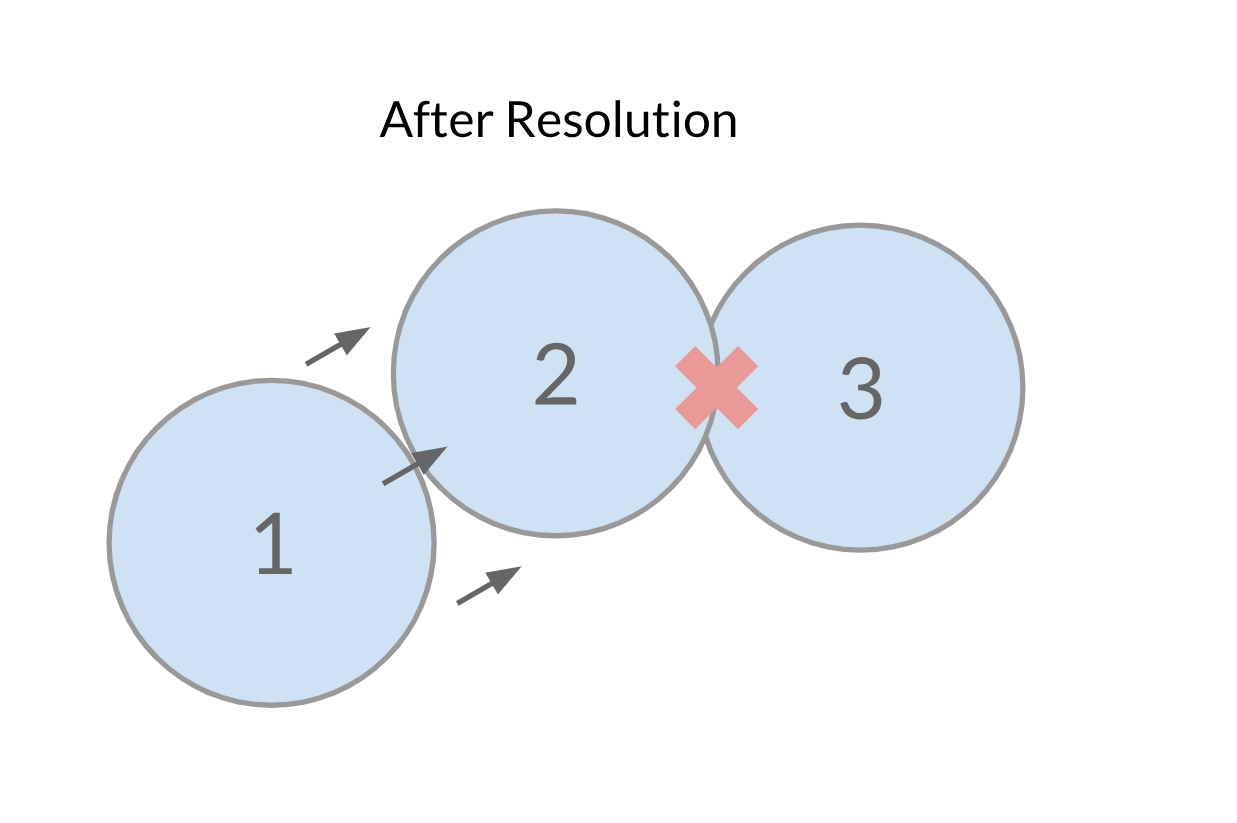 We technically got the first collision resolved, but now we have another one! You could just do one solve every render frame and let this play out over time, but to decrease the number of intersecting colliders at the end of each frame, you can perform multiple iterations of collision resolution every frame.
We technically got the first collision resolved, but now we have another one! You could just do one solve every render frame and let this play out over time, but to decrease the number of intersecting colliders at the end of each frame, you can perform multiple iterations of collision resolution every frame.
Collision solving is going to be a difficult feature to implement. This is not only because it's a pretty difficult 3D math problem, but also because it's heavily reliant on our previous features, namely collision detection. Bear this in mind as we go on to build up this feature; this may be the first time we see serious compromise in one of our engine systems due to the feature being needed yet out of scope.
Getting Started¶
While the 3D math is difficult, the conceptual organization behind collision solving isn't. The important tasks we need to accomplish are (1) figuring out which colliders are actually colliding, (2) figure out where they're colliding on each other, and (3) move them. The first one is very expensive if you perform an O(n^2) check of all colliders against all other colliders, but fortunately as part of our previous collision detection work we implemented a Dynamic Bounding Volume Tree, which is essentially a sorted tree of axis-aligned bounding boxes (AABB) that allows you to cull out most of your collision tests in sparse systems. Unfortunately once we've begun the collision solving process, our colliders will have moved so our Bounding Volume Tree will have been invalidated and we need to regenerate it, but for the time being we're going to ignore that problem. We do plan to address that eventually with a neat little solution using a feature we've already implemented with our Bounding Volume Tree.
So with the first task already out of the way, we can focus on tasks number 2 and 3! Task number 2 is unfortunately still pretty daunting though. To get started, we broke up our collision solving into a case-by-case basis; every individual collider will generate its collision point based on its own shape (i.e. Box, Sphere, or Capsule) regardless of the other collider its intersecting with. This isn't terribly correct because it assumes that our other collider is radially symmetric and that's only true for spheres, but we should first focus on getting our collision points calculated in the first place.
For spheres, calculating the intersection point in this case is trivial—just find the direction of the other collider and get the point out at the radius.
For boxes, we need to check each axis individually to construct the correct intersection point. It seems pretty straightforward at first, but there's actually some tricky parts to it. The naive solution is to check if the point falls outside of the extents of the box on any of the box's local axes, and if so, clamp it to the extents on that axis. That works if our point is outside of the box, but if it's inside of the box, then our collision point doesn't get calculated on the surface of the box—it's calculated on the inside!
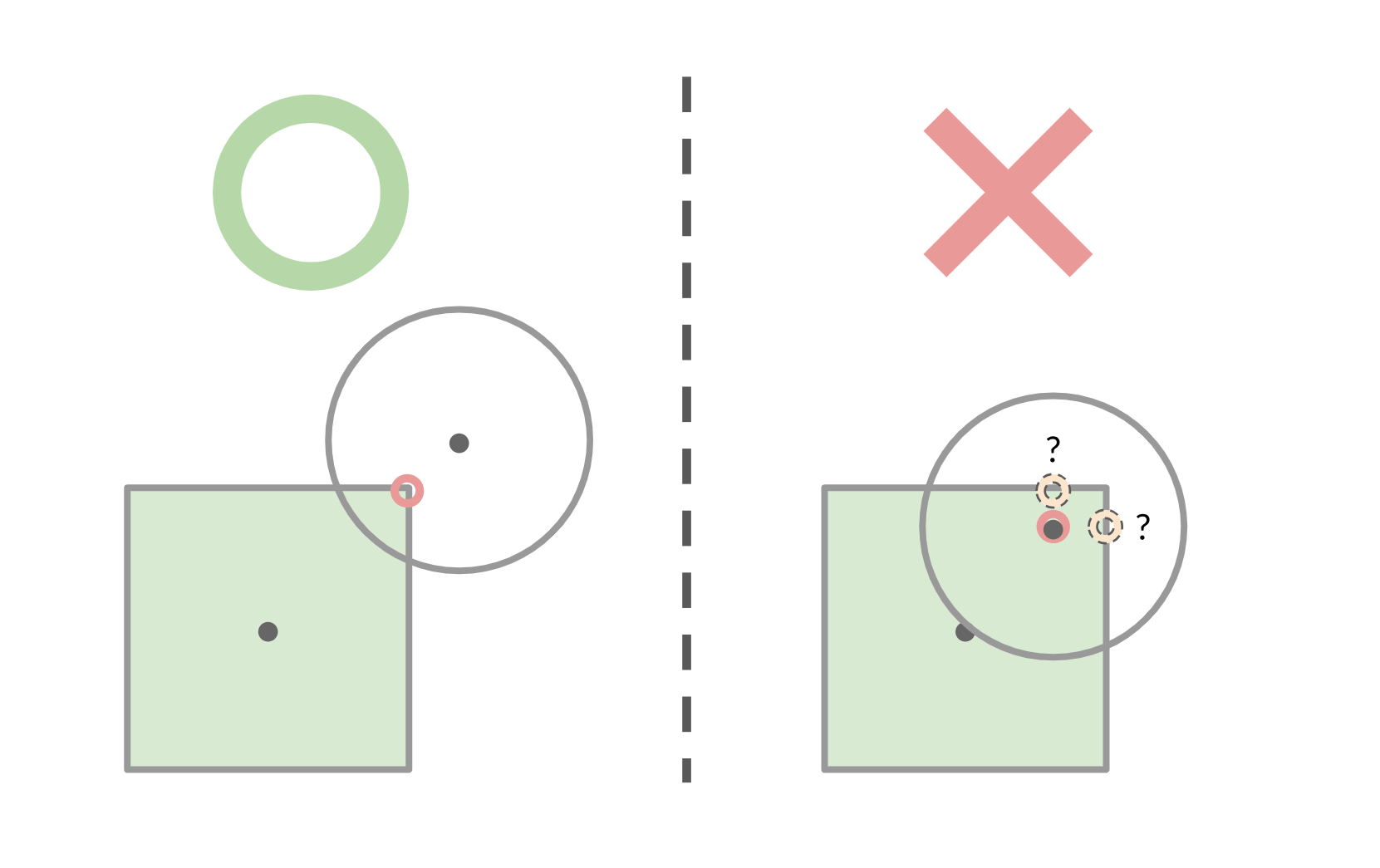
For the time being we don't have this corrected, but in the next week we'll be implementing a solution that will guarantee at least one of the axes is pushed out to the extents so that we have our intersection point on the surface of the box.
Lastly, for capsules, the problem of finding an intersection point may seem daunting since capsules look more complex than spheres or boxes, but in reality it's not that hard. First, we need to calculate the closest point on the "line segment" of the capsule (the inner axis of the capsule that caps off at both radial ends) to our point of interest, which we use our CollisionsModule::ClosestPtPointSegment function for. For the next part, we initially checked if that nearest point on either of the caps of the capsule and restricted the intersection point to certain areas if it was. As it turns out, you don't need to do this! With a line segment, the vector between your point and the line will always be perpendicular to the line if the nearest point isn't on one of its ends, like so:
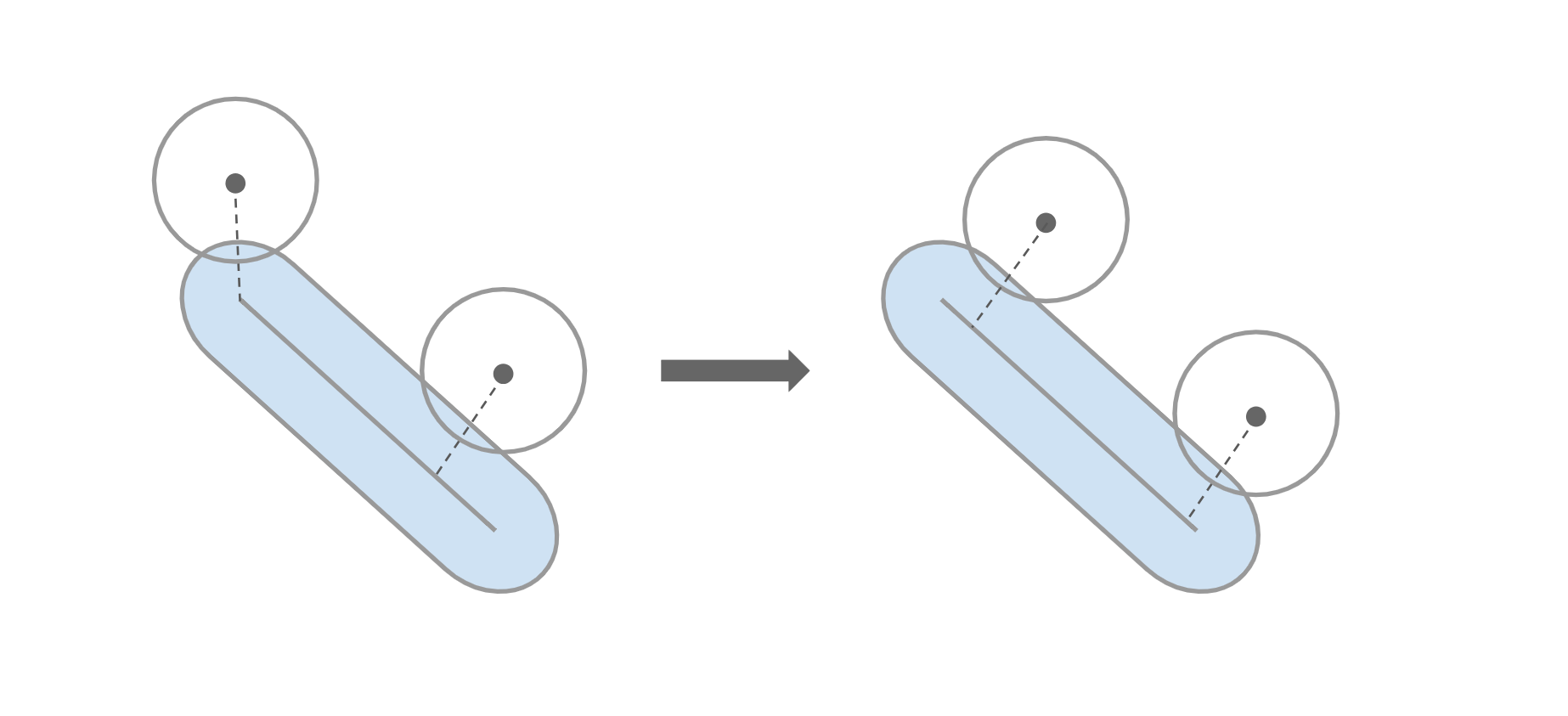
That covers our first pass of work for task number 2; now let's take a swing at task number 3. A very naive solution for moving the colliders once their intersections are solved is to just take the difference vector between the two intersection points and split that between the two colliders (also accounting for any static objects that should be immovable). This indeed works, but we'll discuss later why this isn't correct.
AABB Disarray¶
With our three tasks done, our collision solving should now work, right? Well, earlier we mentioned that the collision solving system relies on our other systems, and here's where all of that came to light! Our AABB's had a few bugs that made the collisions pretty messy and hard to observe, such as accidentally checking against the x value of the AABB's twice instead of also checking the y values during the intersection test, or regenerating each AABB every frame and making our Bounding Volume Tree inaccurate and much more expensive. While we were doing that, we also optimized out some expensive function calls by just using cached data, which is a very common and typically effective optimization trick!
With all of that ironed out and out of the way, let's check our progress on that collision solving!
You know what? We'll take it as a win. But we clearly have more work to do.
How Does Unity Do It?¶
Following the same pattern as we have before, once we realized that our system doesn't quite meet expectations, we did some field research. And by field research, we mean we opened Unity and tried to reverse engineer its own systems. With the following video, you can actually see some interesting behavior that we didn't consider before. The red objects are movable and the white ones are completely immovable, so we're focusing on how the red ones are moved by the collisions:
For our collision solving, the box collisions are notably the poorest as every collider will push away from its face and into one of the corners. In Unity's case, the collisions behave as you'd expect for the most part; when something is being pushed by a box, that thing gets pushed away from the face of the box. What's more interesting is when the box is at an angle to another box—the box whose corner penetrates the other's face is pushed in the direction of the face. This case is annoying to account for because what exactly is the correct solution when a wedge is shoved into something? Do you push it on one side or the other?
This got us thinking about our "generalized" collision solving algorithm and why it was failing so poorly. Ours takes the difference between the two intersection points and displaces the colliders based on that, but that means that whenever colliders are not perfectly aligned with one another, they'll gradually push one another out of the way—even if they're two box colliders that are oriented exactly the same. So our solution for task number 3, moving the colliders, is incorrect. So what's the correct solution then?
Our investigation of Unity's collisions contains the answer. A box collider shoves all other colliders in the direction of its face except for when its wedge is the part that is colliding with the other collider. In the case that the wedge is colliding, then the box collider actually gets moved based on the other collider. This means that the collision resolution is performed on a case-by-case basis, and we need to figure in how the box colliders collide with other colliders to arrive at a proper solution.
A Case-by-Case Solution¶
Our second stab at collision resolution is still not very elegant, but it's getting closer to a workable solution. What we know now is that our collisions should be resolved on a case-by-case basis, with the following ranking: (1) box face, (2) spheres and capsules, (3) box wedge. We only need to be concerned with box colliders for now; if another collider has some similar problem, we'll deal with it after getting some correct box collisions.
Our basic algorithm for the new solution is to check the types of the colliders involved in the collision first, and if either collider is a box, then we need to check whether or not one of the boxes collided on its edge. If they did, then the collision resolution is determined by the other collider. In the case that the box collider actually collides on its face, then we need to figure out which face it was that collided and push in the direction of its normal.
With that implemented, our solution actually isn't looking too terrible!
Future Plans with Collision Solving¶
Right now, we're currently building up a better suite of tooling to test our collisions and collision solving. We just recently added some controls to our Bounding Volume Tree testing level so that we can more easily figure out what's going on when we have over 100 colliders flying around in one level.
Every second is a beautiful frame of expensively contrived behavior.
For the next steps, we've got a few ideas. For one, our box collider intersection detection is incorrect because it can put the intersection point inside of the box, and we have a pretty good idea of how to address that. Our Bounding Volume Tree is also incorrect after the first iteration of our collision solver because we shift around the colliders without regenerating the tree; we could technically regenerate the tree, but that's very expensive, so instead we plan on trying some heuristics for the AABB's to avoid having to ever recalculate the Bounding Volume Tree despite multiple iterations of collision solving. Lastly, our capsule collisions have always looks pretty bad, and the collision resolution for them definitely isn't right, so we'll probably be taking a look into that as well. We would love to do some optimization, but as it stands we can run 50+ colliders in our level at about 60FPS and our target game won't need that many colliders, so optimization isn't exactly a high priority task.
Level Loading¶
Level loading as an engine functionality is simply to be able to unload a level and load another level without the engine systems shutting down (or breaking, crashing, exploding...). Our implementation isn't a sophisticated approach and limits the developer to only having one level loaded at any given point, nor can there be persistent entities, so it could definitely be improved upon. The game developer can call LevelManager::LoadLevel at any point during a frame, then the current frame will finish processing all variable updates, and at the end of the frame the level is unloaded and the next level starts to load. The unload level functionality was already established to prevent memory leakage when shutting down the engine, so we relied on that method heavily. The Level::UnloadLevel worked fine for shutting down the engine, but bugs were found in other components that weren't associated with leaking memory but instead with functionality, so we couldn't observe them after the engine/application closed.
The main bugs of the level loading system were that GUI entities seemed to be infinitely drawn, our debug drawing system's view matrix was corrupted, and mesh models were not being removed. All of these pointed towards something to do with rendering, and while debugging these problems we found that resizing the viewport relieved the issue for a while, but wasn't the source of the problem. We were able to deduce that it wasn't just the GUI or rendering systems by testing different level loads, so what we're looking for is likely something they share in common: The "clear screen" function call and camera. The screen clearing didn't immediately seem to be the problem, so we watched how the camera was being set in the RenderModule. Here, the RenderModule selects the first camera in the list, and in most levels there is only one camera to select from. When we set a breakpoint to watch this region of code, we found that each level's camera was stacking! In CameraComponent::OnEnable, the camera is added to RenderModule's list of cameras for the level; however, CameraComponent::OnDisable wasn't removing it from the list. This can also be found from deactivating the camera component, which confirms that as the source of our problems. Once this was fixed, all of those problems went away!
Another problem we found during our level loading development was from our input system. Input wasn't automatically getting removed for each level. When we took a closer look at our input system, it was clear that we weren't unregistering key bindings; also, deleting the entity was causing undefined functionality, which is another great side-effect enabled by our own memory system. To fix this, we just needed to clear the input in preparation for the next level.
As a result of level loading, we found the need to separate the engine input and gameplay input so that we can clear our input callback map on changing levels, discussed in the Patch Notes.
 The output of loading and unloading the levels from the above video.
The output of loading and unloading the levels from the above video.
Asset Processing Tool¶
The current asset pipeline is focused around Horde3D's needs for models, animations, and materials. The models are processed into .geo and .scene.xml files, the animations into .anim, and the materials into .material.xml files. The other file types aren't compressed or packaged in any other file format, although they probably should to be for better loading speeds by the engine and to yield a smaller memory footprint. Alas, we don't have time for that, so let's just deal with Horde3D's formats.
Horde3DUtil has a COLLADA conversion application that processes .dae (COLLADA) files to these other file formats, but requires the command line to determine which file to process. In weeks prior, we created a simple batch script that process all .dae files in the folder and subfolder of the script into model and animation files. The problem we have now is that, regardless of if the COLLADA file has mesh or animation data, it will produce geo, scene.xml, and .anim files as well as processing all models, even if they haven't been updated or changed since last processing. This script is great to quickly get things done but isn't great for small tweaks or keeping files/memory to a minimum.
We created a tool in WPF to select which file you want processed and what type of output the file should produce. It searches for the base 'Resource' directory, which is required by Horde3D, and everything is based off of that folder. This is what the tool looks like:

We realize that other engines like the Arc80 Engine require more tools for cooking assets so that they can have more control of the data. However, with such a small amount of time, we are just making small, quick tools that will provide us with the most benefit.
GUI¶
Fonts¶
After we added the awesome gameplay that we have in our second game, something really popped out to us; the text was tiny and boring. The team had been contemplating whether or not we should put the effort into getting fonts into the engine, but after seeing this game really hit the nail in the head, we decided to give it a try!
We had already integrated some font functionality into our engine. ...Or so we thought. Soon after we tried to get fonts working, we realized the font functionality wasn't nearly good enough—or even working, really. So we had to rework most of it. Originally the Isetta::Font class was just another name for ImFont, but this also means that the imgui header would need to be included in any file of the game which would like to do anything with font. This felt wrong; it's okay for our GUI class to be included in these source files, but we don't want our external library to be included. To bypass this, we created a "fake" class named Font which derived from imgui's ImFont as well as some static helper functions. The static helper functions help the fonts being stored, so we don't need to reload the fonts and can access shared fonts more easily among multiple classes. This task was fairly easy to implement and well worth the effort—we were able to change the score display of our first game to something much prettier!

AI Pathfinding¶
AI is not necessarily a part of a game engine. Instead, it's more like a replaceable gameplay system built above the underlying game engine, which is why we have AI almost at the top of our architecture diagram. But also, if a game engine is mostly designed for one game or one type of game, some of the AI code can be baked into the game engine. Since our team is quite interested in implementing an AI system, and our game also needs a simple pathfinding algorithm to guide the enemies to avoid obstacles and move towards the players, we decided to implement the AI pathfinding system inside of our engine.
A* Versus Vector Field¶
There are a bunch of pathfinding algorithms in the game AI field, from breadth-first search1 and Dijkstra's algorithm2 to all sorts of A* 3 derivations. How can we find one that fits our game best? Let's look back to what our game AI requires:
- Our game is a top-down twin-stick shooter. Though the game is made in 3D, the players and the enemies can only move in the xz plane.
- Our game can have hundreds of enemies moving independently, and to reduce the pressure of collision detection and solving, the enemies cannot collide with each other.
- Our game environment is fixed. The obstacles on the map will not move and there's no level streaming.
Based on these requirements, we make these conclusions:
- Since the environment is fixed, we can process it before the game starts. One of the most common pre-processing methods is to make the map into a grid.
- Because we can have quite a lot of units calculating their path simultaneously in the same frame, the computation complexity can be significantly higher when it's based on each unit rather than when it's based on each grid cell.
- Even if enemies don't have collisions between each other, we still don't want them always following the same path and overlap with each other, so outputting a fuzzy path is better than one single best solution.
After these considerations, we found that the common A* pathfinding may not be the best one for our game, because it computes separate paths for individual agents even \ though many paths may have similar sections, and it always returns a fixed, heuristically optimized solution. With further research, we found an alternative method, which is to combine vector flow fields4 with steering behaviors5. It can greatly reduce the computation complexity as well as efficiently simulate the hundreds of units on the map.
Building the Vector Field¶
The concept of this pathfinding algorithm is quite straightforward. Since the navigation space is divided into a grid, our calculation is mostly based on the grid cells. The purpose of building a vector field is to calculate what direction a unit should go based on its position and cell relative to its target. To do that, we generally need to build two matrices: The cost matrix and the vector matrix.
The cost matrix is a matrix that stores the path distance from each cell to the target cell. It's not the Euclidean distance which calculates the distance regardless the obstacles. Instead, the path distance is how many cells one unit needs to go through to arrive at the target. We are using a wavefront algorithm to generate the cost matrix, which is basically a breadth-first search that updates its neighbors by its path distance plus one. After the cost matrix generation, we now have a grid like this:
The vector matrix is also quite simple. It is a matrix that each cell points to the gradient of the grid, which is to point to the neighboring cell with the lowest cost (don't forget about the diagonal case!). After this process, the navigation grid looks like this:
One thing that is quite interesting here is when we are adding the sides of the obstacles into the grid, marking the corresponding cells as un-walkable cells, we were actually using the line drawing algorithm we learned from a computer graphics course at our university. This is really an unexpected way we found to relate AI to subjects other than robotics.
Integrating Steering Behaviors¶
Once the vector flow field is calculated, we can know the target direction of each cell by looking up the vector matrix. The last thing we need to do is to naturally steer the units to match the target direction. The algorithm here we used is the velocity matching algorithm6 and the arriving algorithm7. It takes the acceleration, the velocity and the Euclidean distance from the unit to the goal into account and drives the unity smoothly. After the integration, we now have the units approaching the target like this:
There are still some minor features like multiple target support we haven't implemented yet. They will be patched into the engine next week.
Full-Featured Game Demo¶
This past week, we started implementing features of the game we set out to build from the beginning. This game will have slightly more polish than either of the previous games (or other games we end up building) because we'd like this to be a good demonstration of what the engine is capable. As explained in Week 0, the gameplay itself won't be all that fun or exciting, but it will be the capstone of the engine.
So far, we've implemented the main menu and most of the UI needed for the game. The main menu needs to be able to transition the player into single player mode, multiplayer mode, and exiting the game. The multiplayer mode needs to allow the player to opt into hosting a game or to connect to another host player. For the hosting option, this is when we will boot up the server (which has yet to be done for the game), but for the connection option the player must be able to input the IP address of the host. The first iteration of our IP address input system aims for looks over functionality. Using the idea that all IPv48 addresses are 15 digits long, so the IP address can be formatted as xxx.xxx.xxx.xxx. Then when the user types, the x's can be replaced with the number and the . won't change. Which turned out like this:
Then some of the team commented on that IP addresses aren't always 15 digits, as the numbers are actually 0 to 255 and don't need to fill 3 digits, i.e. 000 for 0. So even though the IP addresses could be represented by 15 characters with four sets of three characters, it is inconvenient to ask players to type extra characters if their IP address doesn't use the hundreds or tens places. So removing the nicety of the x's, we just went back to the plain implementation.
When the single player button is clicked, the game then loads the single player level which has the basic health and score UI. The game could have been done in one level by just turning the UI off once the game starts, but then there would menu entities in the game level—this is what forced us to develop the level loading system. Here is what we have so far!
Patch Notes¶
Separating Engine and Gameplay Input¶
The original implementation of the Input and InputModule system was to have specific callback maps for each type of input: mouse, key press/release, etc. However, when the GUIModule system was integrated, the GLFWwindow parameter of the input callback functions was needed for the GUI. We were hiding the GLFWwindow parameter from the input callbacks given to the gameplay developer, so we needed a second set of functions with the GLFWwindow as a parameter. This worked for a while, but it definitely added some confusion about which function the game developer should be subscribing to because they could technically subscribe to the GLFW callback functions. We were also exporting the entire Input class to our DLL. We could have added the "export to DLL" attribute to only the needed functions, but that would be annoying for each additional function.
When we introduced level loading, we were clearing all memory of the previous level, which included anything encapsulated by entities within the level but did not include our input system. If a developer forgot to unregister their input callbacks, then the callback would most likely cause an exception because it would reference deleted memory. We even noticed internally that with some of our own components/levels, even we—the masterful, all-knowing engine developers—were forgetting to unregister our input callbacks. How could we expect the gameplay developers to remember?
The answer was we couldn't, which is why we decided to just clear all input callbacks of the past level when unloading the level. We didn't want to clear the GUIModule connection to the Input however, and if a developer had used the GLFW callbacks, we couldn't clear that callback. So the only way to prevent them from using the GLFW callback functions was to move those into their own class, GLFWInput, which wouldn't be cleared or destroyed until ShutDown. GLFWInput is subsequently not exposed to the game developer and only used for engine internal input; the added benefit here is that there is now less confusion for the game developer of which input callback to subscribe to.
Coming Soon¶
As far as the engine goes, our original feature lock was this past Friday! As you might be able to guess, we're not quite ready to lock down the engine yet, but we sure are close! One more week might allow us to put the finishing touches on our engine systems. (But this might be a busy week!)
We posted our interview with Martin Middleton this past week, which you should definitely check out. We will be posting our interview with Jeff Preshing this week, and in the next couple of weeks we will be putting up several more. In related news, we're submitting our interviews for publication this week, so hopefully we'll have more news on that next time you hear from us!
Resources¶
Not much was added in the resource section this week, but it still remains a great source. We even find ourselves going there to see what the others on the team are using, especially when debugging systems that aren't our own. If you have any resource that you think we should take a look at, please let us know!
Originally Published November 19, 2018.
-
Breadth-first search (BFS) is an algorithm for traversing or searching tree or graph data structures; it starts at the tree root and explores all neighbor nodes before looking at children nodes. ↩
-
Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a graph, which may represent, for example, road networks. It's most common variant finds the shortest path by accumulating distances between node pairs in the path. ↩
-
A* (pronounced "A star") is an algorithm that is widely used in pathfinding and graph traversal. It is an extension of Dijkstra's algorithm that also uses heuristics to guide its search for better performance. ↩
-
A vector field is an assignment of a vector to each point in a subset of space, such as a plan with a collection of arrows with a given magnitude and direction. Vector fields are often used to model the speed and direction of a moving fluid like a river. ↩
-
A steering behavior is a way of applying various forces to a unit's movement to generate realistic behaviors like chasing, fleeing, following, and more. ↩
-
For more about velocity matching algorithm, please read Artificial Intelligence For Games Page 66 ↩
-
For more about arrive algorithm, please read Artificial Intelligence For Games Page 66 ↩
-
Internet Protocol version 4 (IPv4) is the fourth version of the Internet Protocol (IP). It is one of the core protocols of standards-based internetworking methods in the Internet, and does not guarantee delivery or proper sequencing. ↩